Menu
Insight
Standards for Data

Data is the quiet foundation on which the AI empires of the modern age are built. Nowhere is this more true than in robotics. A careful look at the most prominent advances in physical AI in the past year reveals that they are not groundbreaking architectural innovations or step changes in model scale, but rather workarounds for limited or low-quality data, or new pipelines that accept cheaper, more readily available modalities.

In an endless effort to scale up training data and build mindshare in the no-doubt-enormous training data market, the current corpus of robotics data has become a bit of a melting pot. Datasets are growing, but task selection remains repetitive. Datasets are simultaneously a mix of embodiments yet grossly over-represent a handful of hardware vendors, and those embodiments are not necessarily the best ones, just the ones where providers thought to invest money in data collection. Trace quality and sensor modalities remain chaotic, with even some commercial data providers delivering what is obviously sub-par data.
We can draw these lines because we run the whole loop ourselves. PrismaX collects premium, mistake-free teleoperated data on a curated set of embodiments, trains and evaluates models on that data with an in-house team, and feeds what we learn back into how the next batch is collected. We’ve watched, run by run, what separates data that trains a capable model from data that quietly degrades one.
The Standards for Data are the output of that loop: repeatable guidelines for collecting pretraining-grade robotics data, and the reference our validators use to apply them. This is the first arc.
What Data?
One of the first problems you’ll see when interacting with community robotics datasets on HuggingFace is that the idea of “robotics data” isn’t even well-defined: videos, mocap, and teleoperation are all being sold as “good for robotics,” some clearly just rebrands from legacy machine vision or virtual reality datasets.
Our first stake in the ground is:
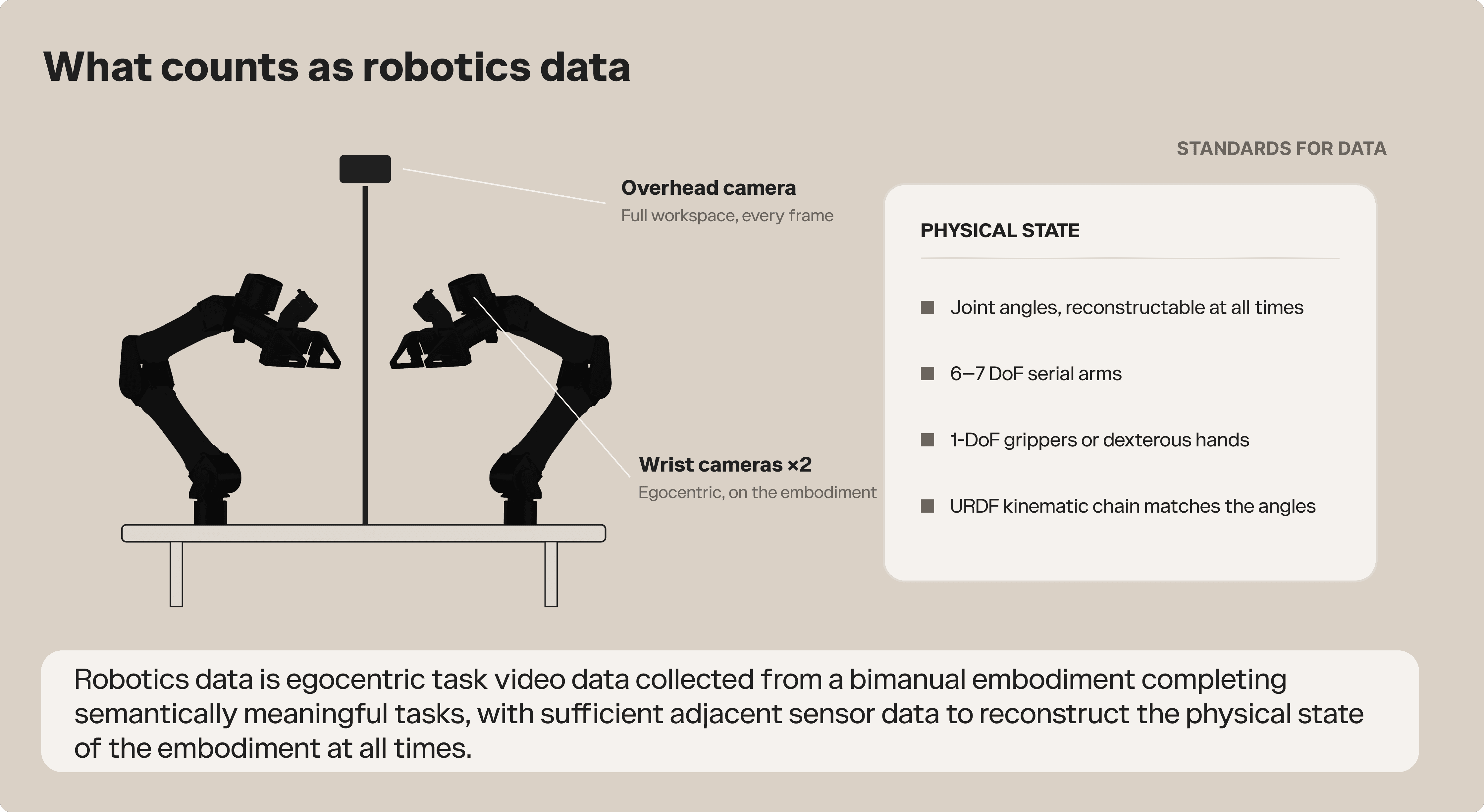
Robotics data is egocentric task video data collected from a bimanual embodiment completing semantically meaningful tasks, with sufficient adjacent sensor data to reconstruct the physical state of the embodiment at all times.
“Egocentric” means the video is recorded from cameras mounted on the embodiment (as opposed to room-scale cameras), and “embodiment” is any robot, UMI-style gripper, or human.
We further require:
On a bimanual embodiment, video data is at a minimum collected from an overhead camera with full view of all relevant areas of the workspace at all times, plus a minimum of one camera on each wrist of the embodiment.
Robotics foundation models are trained to predict physical state from videos. At a minimum, this state is:
The angles of each joint of the robot, such that the physical configuration of the robot can be reconstructed from these angles.
We validate this in part by demanding that new embodiments include a URDF description with a kinematic chain that matches these angles. We also enforce that embodiments have serial kinematic arms with six or seven degrees of freedom and 1-DoF grippers or dexterous hands.
These standards paint the following picture:
In other words, a humanoid-ish robot or human with head and wrist cameras, reasonable joint configurations suitable for cross-embodiment transfer, and sensible image quality, jitter, and sample rate.
All of these requirements are easily enforced at the platform level by software. No human review is needed, so validators start from a clean baseline and spend their judgment where it actually matters: the quality of the demonstration itself.
The Validator’s Job
Everything past that baseline is judgment. Software can take a pass at most of it: whether the hand fumbled the grasp, whether the task on screen matched the prompt, whether the run was a near-copy of the last fifty. But an automated guess is not a standard. A model is only as good as the data it learns from, and the quality of that data is best qualified by a person who can see what actually happened. Automated checks approximate. People judge. That is the work of a validator.
It’s the same pattern behind the language models people use every day. Their fluency traces back to a layer of human judgment scoring what’s good and what isn’t. Robotics is no different. Better models come from better data, and better data comes from real people holding real demonstrations to a standard.
Validators are that human scoring layer: the people who watch each demonstration and decide whether it is training-grade. Some of what they apply is pass/fail. The rest is scored on a sliding scale. The standards below are the rubric behind both.
Pass/Fail Criteria
Overhead camera has full view of the workspace at all times
Any objects and both wrists should be visible in the overhead camera at all times.
Example failures: reaching out-of-frame for an object, a robot with an actuated head camera looking away from an action, egocentric video where one of the hands is sometimes not in the head camera view
Why it matters: The model learns to predict actions from image features, and one of the most important features is the position of the arms in the image. If the arms aren’t visible at all, this can lead to idiosyncratic behavior.
Images and lighting are clear
Every camera should produce a clean, well-lit image for the full episode. Lighting should be bright and even enough to avoid sensor noise, motion blur, and compression artifacts.
Example failures: dim lighting triggering excessive camera noise, leading to blocking artifacts after compression
Why it matters: Lighting should be plausible for the task at hand. If it's so dim that it exposes camera or compression artifacts, the model can learn to look for those artifacts instead of real image features.
Task matches prompt
The task should semantically match the prompt, and actions should be semantically valid.
Example failures: prompt is “make an American-style breakfast” but data is of microwaving toast, prompt is “place shoes in shoeboxes” but data places them in bags instead, prompt is “thread fasteners into holes” but data drops them through unthreaded through-holes
Why it matters: Prompt interpretation is open-ended, so a multi-pass validator check that the interpretation is sensible is important.
Trajectory should be separable
No action should do two things at once, and both arms may only work on one task at a time.
Example failures: picking up two items with one hand, having each arm plate a different plate
Why it matters: Model training pipelines often split long tasks into chunks, then write detailed text labels for each chunk to help the model learn. Overlapping or ambiguous actions make that labeling difficult or impossible.
No struggling
Mistakes should be small and quickly recovered from.
Example failures: repeated attempts to zip a zipper on a container before succeeding, repeatedly missing a connector before plugging it in
Why it matters: Small mistakes are useful. They teach the model how to recover from inadvertent errors. Repeated or lengthy mistakes teach the model to copy the mistakes, which is not what we want.
No non-causal errors
Any mistakes should only affect future actions; mistakes should not undo past actions.
Example failures: spilling a previously-packed container while packing a new one, knocking over a vase, plugging a cable into the wrong charger, going back, and correcting it
Why it matters: Mistakes that undo previous work risk being copied by the model and shouldn’t appear during normal inference, so they serve only a detrimental purpose.
Sliding Scale Criteria
These criteria aren’t pass/fail. Validators score them, and those scores are the human signal that ranks one good run above another.
Trajectory speed
Within the limitations of the hardware, trajectories should approach 1x or higher human speed.
Details: For some tasks which require extensive manipulation that pushes the capabilities of 1-DoF grippers, consistent under-1x speed is acceptable as long as trajectories contain no errors.
Why it matters: Speed transfers directly to the model. The speedier the training data, the better the model.
Trajectory smoothness
Trajectories should have the same confidence as a well-trained human would have in completing the task.
Details: Almost a binary criterion. There should be no pauses, stutters, or uncertainty anywhere along the task.
Why it matters: Like speed, smoothness transfers directly to the model.
Completion quality
Whether mistakes were made during the completion of the task.
Details: See also binary criteria above.
Why it matters: Again, mistakes can be helpful, but too many risk the model learning to repeat them.
Diversity
Compared to other episodes of the same task, how creative was this one?
Details: Keep in mind also “trajectory should be separable.” Excessive innovation in how the task is completed is not a good thing. 0 = exactly the same as another run, 5 = extremely innovative
Why it matters: Data providers tend to be repetitive because it maximizes the hours of data they can produce. Repetitive data is of limited use for training, so validators flag repetition.
Level of completion
How much of the task was completed?
Details: 0 = no attempt was made, 5 = 100% complete
Why it matters: This is almost a binary criterion, but even partially-completed tasks can be turned into usable training data.
Why This Matters
Physical AI is hardware-rich and data-poor. The models being trained today are limited less by architecture than by the data they learn from, and most available data is too narrow, too synthetic, or too inconsistent to teach a model what it needs to know. Standards are how that changes. They give operators a clear target to collect against and give validators a shared rubric to hold the line on quality. Better models start with better data. Better data takes a human willing to hold it to a standard. That’s the difference between training a robot and filling a hard drive.
More to explore




Menu
Insight
Standards for Data
Data is the quiet foundation on which the AI empires of the modern age are built. Nowhere is this more true than in robotics. A careful look at the most prominent advances in physical AI in the past year reveals that they are not groundbreaking architectural innovations or step changes in model scale, but rather workarounds for limited or low-quality data, or new pipelines that accept cheaper, more readily available modalities.
In an endless effort to scale up training data and build mindshare in the no-doubt-enormous training data market, the current corpus of robotics data has become a bit of a melting pot. Datasets are growing, but task selection remains repetitive. Datasets are simultaneously a mix of embodiments yet grossly over-represent a handful of hardware vendors, and those embodiments are not necessarily the best ones, just the ones where providers thought to invest money in data collection. Trace quality and sensor modalities remain chaotic, with even some commercial data providers delivering what is obviously sub-par data.
We can draw these lines because we run the whole loop ourselves. PrismaX collects premium, mistake-free teleoperated data on a curated set of embodiments, trains and evaluates models on that data with an in-house team, and feeds what we learn back into how the next batch is collected. We’ve watched, run by run, what separates data that trains a capable model from data that quietly degrades one.
The Standards for Data are the output of that loop: repeatable guidelines for collecting pretraining-grade robotics data, and the reference our validators use to apply them. This is the first arc.
What Data?
One of the first problems you’ll see when interacting with community robotics datasets on HuggingFace is that the idea of “robotics data” isn’t even well-defined: videos, mocap, and teleoperation are all being sold as “good for robotics,” some clearly just rebrands from legacy machine vision or virtual reality datasets.
Our first stake in the ground is:
Robotics data is egocentric task video data collected from a bimanual embodiment completing semantically meaningful tasks, with sufficient adjacent sensor data to reconstruct the physical state of the embodiment at all times.
“Egocentric” means the video is recorded from cameras mounted on the embodiment (as opposed to room-scale cameras), and “embodiment” is any robot, UMI-style gripper, or human.
We further require:
On a bimanual embodiment, video data is at a minimum collected from an overhead camera with full view of all relevant areas of the workspace at all times, plus a minimum of one camera on each wrist of the embodiment.
Robotics foundation models are trained to predict physical state from videos. At a minimum, this state is:
The angles of each joint of the robot, such that the physical configuration of the robot can be reconstructed from these angles.
We validate this in part by demanding that new embodiments include a URDF description with a kinematic chain that matches these angles. We also enforce that embodiments have serial kinematic arms with six or seven degrees of freedom and 1-DoF grippers or dexterous hands.
These standards paint the following picture:
In other words, a humanoid-ish robot or human with head and wrist cameras, reasonable joint configurations suitable for cross-embodiment transfer, and sensible image quality, jitter, and sample rate.
All of these requirements are easily enforced at the platform level by software. No human review is needed, so validators start from a clean baseline and spend their judgment where it actually matters: the quality of the demonstration itself.
The Validator’s Job
Everything past that baseline is judgment. Software can take a pass at most of it: whether the hand fumbled the grasp, whether the task on screen matched the prompt, whether the run was a near-copy of the last fifty. But an automated guess is not a standard. A model is only as good as the data it learns from, and the quality of that data is best qualified by a person who can see what actually happened. Automated checks approximate. People judge. That is the work of a validator.
It’s the same pattern behind the language models people use every day. Their fluency traces back to a layer of human judgment scoring what’s good and what isn’t. Robotics is no different. Better models come from better data, and better data comes from real people holding real demonstrations to a standard.
Validators are that human scoring layer: the people who watch each demonstration and decide whether it is training-grade. Some of what they apply is pass/fail. The rest is scored on a sliding scale. The standards below are the rubric behind both.
Pass/Fail Criteria
Overhead camera has full view of the workspace at all times
Any objects and both wrists should be visible in the overhead camera at all times.
Example failures: reaching out-of-frame for an object, a robot with an actuated head camera looking away from an action, egocentric video where one of the hands is sometimes not in the head camera view
Why it matters: The model learns to predict actions from image features, and one of the most important features is the position of the arms in the image. If the arms aren’t visible at all, this can lead to idiosyncratic behavior.
Images and lighting are clear
Every camera should produce a clean, well-lit image for the full episode. Lighting should be bright and even enough to avoid sensor noise, motion blur, and compression artifacts.
Example failures: dim lighting triggering excessive camera noise, leading to blocking artifacts after compression
Why it matters: Lighting should be plausible for the task at hand. If it's so dim that it exposes camera or compression artifacts, the model can learn to look for those artifacts instead of real image features.
Task matches prompt
The task should semantically match the prompt, and actions should be semantically valid.
Example failures: prompt is “make an American-style breakfast” but data is of microwaving toast, prompt is “place shoes in shoeboxes” but data places them in bags instead, prompt is “thread fasteners into holes” but data drops them through unthreaded through-holes
Why it matters: Prompt interpretation is open-ended, so a multi-pass validator check that the interpretation is sensible is important.
Trajectory should be separable
No action should do two things at once, and both arms may only work on one task at a time.
Example failures: picking up two items with one hand, having each arm plate a different plate
Why it matters: Model training pipelines often split long tasks into chunks, then write detailed text labels for each chunk to help the model learn. Overlapping or ambiguous actions make that labeling difficult or impossible.
No struggling
Mistakes should be small and quickly recovered from.
Example failures: repeated attempts to zip a zipper on a container before succeeding, repeatedly missing a connector before plugging it in
Why it matters: Small mistakes are useful. They teach the model how to recover from inadvertent errors. Repeated or lengthy mistakes teach the model to copy the mistakes, which is not what we want.
No non-causal errors
Any mistakes should only affect future actions; mistakes should not undo past actions.
Example failures: spilling a previously-packed container while packing a new one, knocking over a vase, plugging a cable into the wrong charger, going back, and correcting it
Why it matters: Mistakes that undo previous work risk being copied by the model and shouldn’t appear during normal inference, so they serve only a detrimental purpose.
Sliding Scale Criteria
These criteria aren’t pass/fail. Validators score them, and those scores are the human signal that ranks one good run above another.
Trajectory speed
Within the limitations of the hardware, trajectories should approach 1x or higher human speed.
Details: For some tasks which require extensive manipulation that pushes the capabilities of 1-DoF grippers, consistent under-1x speed is acceptable as long as trajectories contain no errors.
Why it matters: Speed transfers directly to the model. The speedier the training data, the better the model.
Trajectory smoothness
Trajectories should have the same confidence as a well-trained human would have in completing the task.
Details: Almost a binary criterion. There should be no pauses, stutters, or uncertainty anywhere along the task.
Why it matters: Like speed, smoothness transfers directly to the model.
Completion quality
Whether mistakes were made during the completion of the task.
Details: See also binary criteria above.
Why it matters: Again, mistakes can be helpful, but too many risk the model learning to repeat them.
Diversity
Compared to other episodes of the same task, how creative was this one?
Details: Keep in mind also “trajectory should be separable.” Excessive innovation in how the task is completed is not a good thing. 0 = exactly the same as another run, 5 = extremely innovative
Why it matters: Data providers tend to be repetitive because it maximizes the hours of data they can produce. Repetitive data is of limited use for training, so validators flag repetition.
Level of completion
How much of the task was completed?
Details: 0 = no attempt was made, 5 = 100% complete
Why it matters: This is almost a binary criterion, but even partially-completed tasks can be turned into usable training data.
Why This Matters
Physical AI is hardware-rich and data-poor. The models being trained today are limited less by architecture than by the data they learn from, and most available data is too narrow, too synthetic, or too inconsistent to teach a model what it needs to know. Standards are how that changes. They give operators a clear target to collect against and give validators a shared rubric to hold the line on quality. Better models start with better data. Better data takes a human willing to hold it to a standard. That’s the difference between training a robot and filling a hard drive.
More to explore
Menu
Insight
Standards for Data
Data is the quiet foundation on which the AI empires of the modern age are built. Nowhere is this more true than in robotics. A careful look at the most prominent advances in physical AI in the past year reveals that they are not groundbreaking architectural innovations or step changes in model scale, but rather workarounds for limited or low-quality data, or new pipelines that accept cheaper, more readily available modalities.
In an endless effort to scale up training data and build mindshare in the no-doubt-enormous training data market, the current corpus of robotics data has become a bit of a melting pot. Datasets are growing, but task selection remains repetitive. Datasets are simultaneously a mix of embodiments yet grossly over-represent a handful of hardware vendors, and those embodiments are not necessarily the best ones, just the ones where providers thought to invest money in data collection. Trace quality and sensor modalities remain chaotic, with even some commercial data providers delivering what is obviously sub-par data.
We can draw these lines because we run the whole loop ourselves. PrismaX collects premium, mistake-free teleoperated data on a curated set of embodiments, trains and evaluates models on that data with an in-house team, and feeds what we learn back into how the next batch is collected. We’ve watched, run by run, what separates data that trains a capable model from data that quietly degrades one.
The Standards for Data are the output of that loop: repeatable guidelines for collecting pretraining-grade robotics data, and the reference our validators use to apply them. This is the first arc.
What Data?
One of the first problems you’ll see when interacting with community robotics datasets on HuggingFace is that the idea of “robotics data” isn’t even well-defined: videos, mocap, and teleoperation are all being sold as “good for robotics,” some clearly just rebrands from legacy machine vision or virtual reality datasets.
Our first stake in the ground is:
Robotics data is egocentric task video data collected from a bimanual embodiment completing semantically meaningful tasks, with sufficient adjacent sensor data to reconstruct the physical state of the embodiment at all times.
“Egocentric” means the video is recorded from cameras mounted on the embodiment (as opposed to room-scale cameras), and “embodiment” is any robot, UMI-style gripper, or human.
We further require:
On a bimanual embodiment, video data is at a minimum collected from an overhead camera with full view of all relevant areas of the workspace at all times, plus a minimum of one camera on each wrist of the embodiment.
Robotics foundation models are trained to predict physical state from videos. At a minimum, this state is:
The angles of each joint of the robot, such that the physical configuration of the robot can be reconstructed from these angles.
We validate this in part by demanding that new embodiments include a URDF description with a kinematic chain that matches these angles. We also enforce that embodiments have serial kinematic arms with six or seven degrees of freedom and 1-DoF grippers or dexterous hands.
These standards paint the following picture:
In other words, a humanoid-ish robot or human with head and wrist cameras, reasonable joint configurations suitable for cross-embodiment transfer, and sensible image quality, jitter, and sample rate.
All of these requirements are easily enforced at the platform level by software. No human review is needed, so validators start from a clean baseline and spend their judgment where it actually matters: the quality of the demonstration itself.
The Validator’s Job
Everything past that baseline is judgment. Software can take a pass at most of it: whether the hand fumbled the grasp, whether the task on screen matched the prompt, whether the run was a near-copy of the last fifty. But an automated guess is not a standard. A model is only as good as the data it learns from, and the quality of that data is best qualified by a person who can see what actually happened. Automated checks approximate. People judge. That is the work of a validator.
It’s the same pattern behind the language models people use every day. Their fluency traces back to a layer of human judgment scoring what’s good and what isn’t. Robotics is no different. Better models come from better data, and better data comes from real people holding real demonstrations to a standard.
Validators are that human scoring layer: the people who watch each demonstration and decide whether it is training-grade. Some of what they apply is pass/fail. The rest is scored on a sliding scale. The standards below are the rubric behind both.
Pass/Fail Criteria
Overhead camera has full view of the workspace at all times
Any objects and both wrists should be visible in the overhead camera at all times.
Example failures: reaching out-of-frame for an object, a robot with an actuated head camera looking away from an action, egocentric video where one of the hands is sometimes not in the head camera view
Why it matters: The model learns to predict actions from image features, and one of the most important features is the position of the arms in the image. If the arms aren’t visible at all, this can lead to idiosyncratic behavior.
Images and lighting are clear
Every camera should produce a clean, well-lit image for the full episode. Lighting should be bright and even enough to avoid sensor noise, motion blur, and compression artifacts.
Example failures: dim lighting triggering excessive camera noise, leading to blocking artifacts after compression
Why it matters: Lighting should be plausible for the task at hand. If it's so dim that it exposes camera or compression artifacts, the model can learn to look for those artifacts instead of real image features.
Task matches prompt
The task should semantically match the prompt, and actions should be semantically valid.
Example failures: prompt is “make an American-style breakfast” but data is of microwaving toast, prompt is “place shoes in shoeboxes” but data places them in bags instead, prompt is “thread fasteners into holes” but data drops them through unthreaded through-holes
Why it matters: Prompt interpretation is open-ended, so a multi-pass validator check that the interpretation is sensible is important.
Trajectory should be separable
No action should do two things at once, and both arms may only work on one task at a time.
Example failures: picking up two items with one hand, having each arm plate a different plate
Why it matters: Model training pipelines often split long tasks into chunks, then write detailed text labels for each chunk to help the model learn. Overlapping or ambiguous actions make that labeling difficult or impossible.
No struggling
Mistakes should be small and quickly recovered from.
Example failures: repeated attempts to zip a zipper on a container before succeeding, repeatedly missing a connector before plugging it in
Why it matters: Small mistakes are useful. They teach the model how to recover from inadvertent errors. Repeated or lengthy mistakes teach the model to copy the mistakes, which is not what we want.
No non-causal errors
Any mistakes should only affect future actions; mistakes should not undo past actions.
Example failures: spilling a previously-packed container while packing a new one, knocking over a vase, plugging a cable into the wrong charger, going back, and correcting it
Why it matters: Mistakes that undo previous work risk being copied by the model and shouldn’t appear during normal inference, so they serve only a detrimental purpose.
Sliding Scale Criteria
These criteria aren’t pass/fail. Validators score them, and those scores are the human signal that ranks one good run above another.
Trajectory speed
Within the limitations of the hardware, trajectories should approach 1x or higher human speed.
Details: For some tasks which require extensive manipulation that pushes the capabilities of 1-DoF grippers, consistent under-1x speed is acceptable as long as trajectories contain no errors.
Why it matters: Speed transfers directly to the model. The speedier the training data, the better the model.
Trajectory smoothness
Trajectories should have the same confidence as a well-trained human would have in completing the task.
Details: Almost a binary criterion. There should be no pauses, stutters, or uncertainty anywhere along the task.
Why it matters: Like speed, smoothness transfers directly to the model.
Completion quality
Whether mistakes were made during the completion of the task.
Details: See also binary criteria above.
Why it matters: Again, mistakes can be helpful, but too many risk the model learning to repeat them.
Diversity
Compared to other episodes of the same task, how creative was this one?
Details: Keep in mind also “trajectory should be separable.” Excessive innovation in how the task is completed is not a good thing. 0 = exactly the same as another run, 5 = extremely innovative
Why it matters: Data providers tend to be repetitive because it maximizes the hours of data they can produce. Repetitive data is of limited use for training, so validators flag repetition.
Level of completion
How much of the task was completed?
Details: 0 = no attempt was made, 5 = 100% complete
Why it matters: This is almost a binary criterion, but even partially-completed tasks can be turned into usable training data.
Why This Matters
Physical AI is hardware-rich and data-poor. The models being trained today are limited less by architecture than by the data they learn from, and most available data is too narrow, too synthetic, or too inconsistent to teach a model what it needs to know. Standards are how that changes. They give operators a clear target to collect against and give validators a shared rubric to hold the line on quality. Better models start with better data. Better data takes a human willing to hold it to a standard. That’s the difference between training a robot and filling a hard drive.