Menu
Insight
Not All Robotics Data Is Created Equal

Everyone is selling robotics data. Most of it isn't what you actually need.
The market has filled up fast — egocentric video companies, motion-capture rigs, synthetic-data shops, gripper-based collection systems. A new egocentric video data company seems to launch every week. On the surface they all look interchangeable. They aren't. The right kind of data depends entirely on what you're training, and that's the question almost no one is asking before the check gets cut.
What does good data actually look like? Worth answering, but the answer starts the same way every time: it depends on what you're training.
What is robotics data, anyway?
We get this question more than you’d expect, so it’s worth answering. Physical AI falls broadly into one of two categories:
Reinforcement learning models are used for low-level kinematic control of robots. The training objective is usually very simple, something along the lines of ‘follow these reference trajectories as closely as possible,’ and the model ‘learns’ the physics of the overall system in a way which can be efficiently deployed on the robot.
Foundation models are used for high-level task completion. These models are trained using what the industry calls ‘imitation learning,’ but in actuality, this is the same sort of weakly supervised learning used to train language models. The model is trained to predict physical actions (joint angles, forces, speeds, etc.) based on prompts and sensor data.
These two paths have vastly different training mindsets, to the point where we would argue they are essentially two disparate fields linked only by the hardware they utilize.
Kinematics Models
Kinematics models do one thing and one thing only. We do not expect a model trained for galloping to also generalize to jumping, nor do we expect models trained on one robot to operate on another type of robot.
These models are trained using what the industry calls ‘sim2real’, which you’ve probably heard of before. Like any AI model, the model is initialized with random weights, which causes the robot to move randomly. For obvious reasons, we cannot deploy the model on hardware and let it flail around millions of times, so we let a simulated copy of the robot do the flailing and hope the simulation results transfer into real robots.
Kinematics does need data, but these data are generally rather small samples for behavior or gait cloning. As mentioned above, the reinforcement learning training pipelines often look like ‘follow this sample,’ and we do need to find samples to follow.
Source: Swarm of Anymal C from ETHZ in Omniverse Isaac sim | Trained on Nvidia 3060 GPU (speeded 4X)
Foundation Models
The goal of foundation models is to generalize to new environments and unseen circumstances. A foundation model that simply copies its training data is not very useful. Secondarily, it would be nice to generalize to new robots with minimal friction.
The industry has converged on a vision-driven architecture where models are trained to generate actions from videos. To train these models, we collect large amounts of data (10Ks to millions of hours) from real robots (or humans, grippers, etc.), extract the actions, and fit the model to this data.
How to Spot the Difference
If you’ve seen an impressive robot performance on social media in the past few months, most of the science was probably of the first type (kinematics model). If you’ve looked at starting a physical AI company or read a fundraising announcement this quarter, it was probably for a company dealing with the second type (foundation model).


Here at PrismaX, we focus almost exclusively on robotics foundation models. Kinematics is amazing, and we all love dynamic robots, but the fact of the matter is that most people would rather buy a robot that does the dishes than one that can do a double wall jump followed by a front flip.
What data do you need for foundation models?
We need to collect pairs of [video, action] data of something (an ‘embodiment’) completing a task. What that embodiment is ends up being surprisingly polarizing right now.
The bread and butter of the industry is to remotely control robots (‘teleoperation’) to complete a task, record data from those robots, and train a model to replay those tasks. Teleoperation is a reliable way to train models, and many of the existing foundation models are trained on this type of data. The drawback is that teleoperation is a bit slow (humans are rarely as fast at completing tasks through teleop as they are natively), and there are some Capex costs associated with bringing up the hardware.
The opposite approach is to record videos of humans completing tasks, then use these videos to train the model. This is free to bring up, and the trajectories are very smooth, but there is a huge cross-embodiment gap (some dynamic motions may be well outside of the capabilities of the hardware), and a lot of human video providers are not very good at managing quality.
An in-between approach is to have humans use a gripper-like tool to complete tasks and a tracking system to measure the gripper's precise location in space. There have been a few successes here (Generalist, Sunday), but the jury is still out on how viable this is for large-scale training. None of the practitioners has disclosed publicly verifiable models or benchmarks yet.
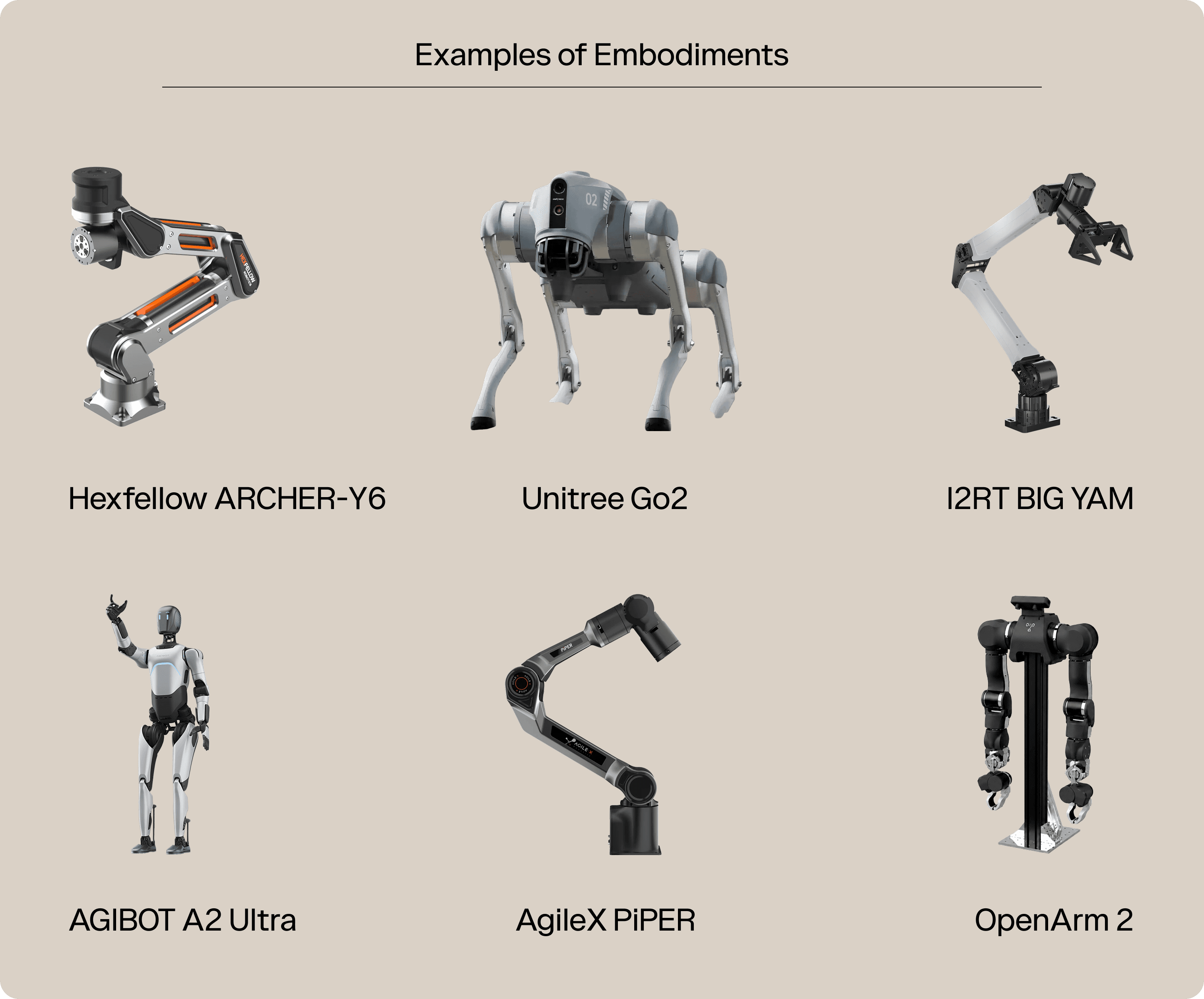
Within teleoperation, there is, of course, the decision on which robots to teleoperate. This creates additional diversity in embodiments, which may or may not be a good thing.
As a service provider, we at PrismaX have no particular preference for any of these embodiments: all share the critical quality, dispatch, and coordination controls we’ve developed, and we’re generally happy to work with whatever the customers’ needs are. As robotics practitioners ourselves, we have a preference for teleoperation; teleoperated data is usually higher quality and easier to work with for our AI scientists, which means we can see results sooner.
Data Quality
We can now try to answer what quality data means. Data quality is driven by prevalent training pipelines that are being used by practitioners in the field right now, so they are as much driven by science as by practical concerns.
Let’s get one thing clear: in the absence of any of these practical concerns (infinite money, infinite robots, infinitely fast computers), the only right answer is to scale a massive and organically generated dataset of tasks being successfully completed in real life and train an equally massive foundation model. This guarantees a lack of bias, robustness to edge cases, and generalization.
Unfortunately, robotics is engineering, not science, so we need to keep a few things in mind:
Computers are finitely fast and probably not going to get that much faster (rest in peace, Dennard). It’s a bit silly to demand the entire model fits on the robot, but we would like model inference not to consume the power of a small town.
Robotics companies have a finite amount of money and talent and need to show results in months, not years. If your ‘common crawl for the real world’ won’t be finished in three years, that’s three years where you aren’t getting customers.
Big datasets need big models to fit properly, so even after you have your common crawl for the real world, the model you train on it might not fit on the robot.
The sum of these practical concerns is that robotics pretraining looks a lot like language model post-training: it’s a predicate that the data be very high quality, free of mistakes, and generated by the top data collectors, but besides that, intelligently controlling the distribution of the data is essential to make progress.
This intelligent control is a big part of what we offer. Because we have a top-tier in-house robotics team, we actually understand what datasets need to look like, what should vary, and what should stay the same to achieve models with high accuracy and reasonable convergence time. As a result, the data we collect, whatever the modality (be it teleop, grippers, or video), are held to the same high standards that we would use if we trained our own models, and we’ll work with you to customize those datasets for your vision.




Menu
Insight
Not All Robotics Data Is Created Equal
Everyone is selling robotics data. Most of it isn't what you actually need.
The market has filled up fast — egocentric video companies, motion-capture rigs, synthetic-data shops, gripper-based collection systems. A new egocentric video data company seems to launch every week. On the surface they all look interchangeable. They aren't. The right kind of data depends entirely on what you're training, and that's the question almost no one is asking before the check gets cut.
What does good data actually look like? Worth answering, but the answer starts the same way every time: it depends on what you're training.
What is robotics data, anyway?
We get this question more than you’d expect, so it’s worth answering. Physical AI falls broadly into one of two categories:
Reinforcement learning models are used for low-level kinematic control of robots. The training objective is usually very simple, something along the lines of ‘follow these reference trajectories as closely as possible,’ and the model ‘learns’ the physics of the overall system in a way which can be efficiently deployed on the robot.
Foundation models are used for high-level task completion. These models are trained using what the industry calls ‘imitation learning,’ but in actuality, this is the same sort of weakly supervised learning used to train language models. The model is trained to predict physical actions (joint angles, forces, speeds, etc.) based on prompts and sensor data.
These two paths have vastly different training mindsets, to the point where we would argue they are essentially two disparate fields linked only by the hardware they utilize.
Kinematics Models
Kinematics models do one thing and one thing only. We do not expect a model trained for galloping to also generalize to jumping, nor do we expect models trained on one robot to operate on another type of robot.
These models are trained using what the industry calls ‘sim2real’, which you’ve probably heard of before. Like any AI model, the model is initialized with random weights, which causes the robot to move randomly. For obvious reasons, we cannot deploy the model on hardware and let it flail around millions of times, so we let a simulated copy of the robot do the flailing and hope the simulation results transfer into real robots.
Kinematics does need data, but these data are generally rather small samples for behavior or gait cloning. As mentioned above, the reinforcement learning training pipelines often look like ‘follow this sample,’ and we do need to find samples to follow.
Source: Swarm of Anymal C from ETHZ in Omniverse Isaac sim | Trained on Nvidia 3060 GPU (speeded 4X)
Foundation Models
The goal of foundation models is to generalize to new environments and unseen circumstances. A foundation model that simply copies its training data is not very useful. Secondarily, it would be nice to generalize to new robots with minimal friction.
The industry has converged on a vision-driven architecture where models are trained to generate actions from videos. To train these models, we collect large amounts of data (10Ks to millions of hours) from real robots (or humans, grippers, etc.), extract the actions, and fit the model to this data.
How to Spot the Difference
If you’ve seen an impressive robot performance on social media in the past few months, most of the science was probably of the first type (kinematics model). If you’ve looked at starting a physical AI company or read a fundraising announcement this quarter, it was probably for a company dealing with the second type (foundation model).
Here at PrismaX, we focus almost exclusively on robotics foundation models. Kinematics is amazing, and we all love dynamic robots, but the fact of the matter is that most people would rather buy a robot that does the dishes than one that can do a double wall jump followed by a front flip.
What data do you need for foundation models?
We need to collect pairs of [video, action] data of something (an ‘embodiment’) completing a task. What that embodiment is ends up being surprisingly polarizing right now.
The bread and butter of the industry is to remotely control robots (‘teleoperation’) to complete a task, record data from those robots, and train a model to replay those tasks. Teleoperation is a reliable way to train models, and many of the existing foundation models are trained on this type of data. The drawback is that teleoperation is a bit slow (humans are rarely as fast at completing tasks through teleop as they are natively), and there are some Capex costs associated with bringing up the hardware.
The opposite approach is to record videos of humans completing tasks, then use these videos to train the model. This is free to bring up, and the trajectories are very smooth, but there is a huge cross-embodiment gap (some dynamic motions may be well outside of the capabilities of the hardware), and a lot of human video providers are not very good at managing quality.
An in-between approach is to have humans use a gripper-like tool to complete tasks and a tracking system to measure the gripper's precise location in space. There have been a few successes here (Generalist, Sunday), but the jury is still out on how viable this is for large-scale training. None of the practitioners has disclosed publicly verifiable models or benchmarks yet.
Within teleoperation, there is, of course, the decision on which robots to teleoperate. This creates additional diversity in embodiments, which may or may not be a good thing.
As a service provider, we at PrismaX have no particular preference for any of these embodiments: all share the critical quality, dispatch, and coordination controls we’ve developed, and we’re generally happy to work with whatever the customers’ needs are. As robotics practitioners ourselves, we have a preference for teleoperation; teleoperated data is usually higher quality and easier to work with for our AI scientists, which means we can see results sooner.
Data Quality
We can now try to answer what quality data means. Data quality is driven by prevalent training pipelines that are being used by practitioners in the field right now, so they are as much driven by science as by practical concerns.
Let’s get one thing clear: in the absence of any of these practical concerns (infinite money, infinite robots, infinitely fast computers), the only right answer is to scale a massive and organically generated dataset of tasks being successfully completed in real life and train an equally massive foundation model. This guarantees a lack of bias, robustness to edge cases, and generalization.
Unfortunately, robotics is engineering, not science, so we need to keep a few things in mind:
Computers are finitely fast and probably not going to get that much faster (rest in peace, Dennard). It’s a bit silly to demand the entire model fits on the robot, but we would like model inference not to consume the power of a small town.
Robotics companies have a finite amount of money and talent and need to show results in months, not years. If your ‘common crawl for the real world’ won’t be finished in three years, that’s three years where you aren’t getting customers.
Big datasets need big models to fit properly, so even after you have your common crawl for the real world, the model you train on it might not fit on the robot.
The sum of these practical concerns is that robotics pretraining looks a lot like language model post-training: it’s a predicate that the data be very high quality, free of mistakes, and generated by the top data collectors, but besides that, intelligently controlling the distribution of the data is essential to make progress.
This intelligent control is a big part of what we offer. Because we have a top-tier in-house robotics team, we actually understand what datasets need to look like, what should vary, and what should stay the same to achieve models with high accuracy and reasonable convergence time. As a result, the data we collect, whatever the modality (be it teleop, grippers, or video), are held to the same high standards that we would use if we trained our own models, and we’ll work with you to customize those datasets for your vision.
More to explore
Menu
Insight
Not All Robotics Data Is Created Equal
Everyone is selling robotics data. Most of it isn't what you actually need.
The market has filled up fast — egocentric video companies, motion-capture rigs, synthetic-data shops, gripper-based collection systems. A new egocentric video data company seems to launch every week. On the surface they all look interchangeable. They aren't. The right kind of data depends entirely on what you're training, and that's the question almost no one is asking before the check gets cut.
What does good data actually look like? Worth answering, but the answer starts the same way every time: it depends on what you're training.
What is robotics data, anyway?
We get this question more than you’d expect, so it’s worth answering. Physical AI falls broadly into one of two categories:
Reinforcement learning models are used for low-level kinematic control of robots. The training objective is usually very simple, something along the lines of ‘follow these reference trajectories as closely as possible,’ and the model ‘learns’ the physics of the overall system in a way which can be efficiently deployed on the robot.
Foundation models are used for high-level task completion. These models are trained using what the industry calls ‘imitation learning,’ but in actuality, this is the same sort of weakly supervised learning used to train language models. The model is trained to predict physical actions (joint angles, forces, speeds, etc.) based on prompts and sensor data.
These two paths have vastly different training mindsets, to the point where we would argue they are essentially two disparate fields linked only by the hardware they utilize.
Kinematics Models
Kinematics models do one thing and one thing only. We do not expect a model trained for galloping to also generalize to jumping, nor do we expect models trained on one robot to operate on another type of robot.
These models are trained using what the industry calls ‘sim2real’, which you’ve probably heard of before. Like any AI model, the model is initialized with random weights, which causes the robot to move randomly. For obvious reasons, we cannot deploy the model on hardware and let it flail around millions of times, so we let a simulated copy of the robot do the flailing and hope the simulation results transfer into real robots.
Kinematics does need data, but these data are generally rather small samples for behavior or gait cloning. As mentioned above, the reinforcement learning training pipelines often look like ‘follow this sample,’ and we do need to find samples to follow.
Source: Swarm of Anymal C from ETHZ in Omniverse Isaac sim | Trained on Nvidia 3060 GPU (speeded 4X)
Foundation Models
The goal of foundation models is to generalize to new environments and unseen circumstances. A foundation model that simply copies its training data is not very useful. Secondarily, it would be nice to generalize to new robots with minimal friction.
The industry has converged on a vision-driven architecture where models are trained to generate actions from videos. To train these models, we collect large amounts of data (10Ks to millions of hours) from real robots (or humans, grippers, etc.), extract the actions, and fit the model to this data.
How to Spot the Difference
If you’ve seen an impressive robot performance on social media in the past few months, most of the science was probably of the first type (kinematics model). If you’ve looked at starting a physical AI company or read a fundraising announcement this quarter, it was probably for a company dealing with the second type (foundation model).
Here at PrismaX, we focus almost exclusively on robotics foundation models. Kinematics is amazing, and we all love dynamic robots, but the fact of the matter is that most people would rather buy a robot that does the dishes than one that can do a double wall jump followed by a front flip.
What data do you need for foundation models?
We need to collect pairs of [video, action] data of something (an ‘embodiment’) completing a task. What that embodiment is ends up being surprisingly polarizing right now.
The bread and butter of the industry is to remotely control robots (‘teleoperation’) to complete a task, record data from those robots, and train a model to replay those tasks. Teleoperation is a reliable way to train models, and many of the existing foundation models are trained on this type of data. The drawback is that teleoperation is a bit slow (humans are rarely as fast at completing tasks through teleop as they are natively), and there are some Capex costs associated with bringing up the hardware.
The opposite approach is to record videos of humans completing tasks, then use these videos to train the model. This is free to bring up, and the trajectories are very smooth, but there is a huge cross-embodiment gap (some dynamic motions may be well outside of the capabilities of the hardware), and a lot of human video providers are not very good at managing quality.
An in-between approach is to have humans use a gripper-like tool to complete tasks and a tracking system to measure the gripper's precise location in space. There have been a few successes here (Generalist, Sunday), but the jury is still out on how viable this is for large-scale training. None of the practitioners has disclosed publicly verifiable models or benchmarks yet.
Within teleoperation, there is, of course, the decision on which robots to teleoperate. This creates additional diversity in embodiments, which may or may not be a good thing.
As a service provider, we at PrismaX have no particular preference for any of these embodiments: all share the critical quality, dispatch, and coordination controls we’ve developed, and we’re generally happy to work with whatever the customers’ needs are. As robotics practitioners ourselves, we have a preference for teleoperation; teleoperated data is usually higher quality and easier to work with for our AI scientists, which means we can see results sooner.
Data Quality
We can now try to answer what quality data means. Data quality is driven by prevalent training pipelines that are being used by practitioners in the field right now, so they are as much driven by science as by practical concerns.
Let’s get one thing clear: in the absence of any of these practical concerns (infinite money, infinite robots, infinitely fast computers), the only right answer is to scale a massive and organically generated dataset of tasks being successfully completed in real life and train an equally massive foundation model. This guarantees a lack of bias, robustness to edge cases, and generalization.
Unfortunately, robotics is engineering, not science, so we need to keep a few things in mind:
Computers are finitely fast and probably not going to get that much faster (rest in peace, Dennard). It’s a bit silly to demand the entire model fits on the robot, but we would like model inference not to consume the power of a small town.
Robotics companies have a finite amount of money and talent and need to show results in months, not years. If your ‘common crawl for the real world’ won’t be finished in three years, that’s three years where you aren’t getting customers.
Big datasets need big models to fit properly, so even after you have your common crawl for the real world, the model you train on it might not fit on the robot.
The sum of these practical concerns is that robotics pretraining looks a lot like language model post-training: it’s a predicate that the data be very high quality, free of mistakes, and generated by the top data collectors, but besides that, intelligently controlling the distribution of the data is essential to make progress.
This intelligent control is a big part of what we offer. Because we have a top-tier in-house robotics team, we actually understand what datasets need to look like, what should vary, and what should stay the same to achieve models with high accuracy and reasonable convergence time. As a result, the data we collect, whatever the modality (be it teleop, grippers, or video), are held to the same high standards that we would use if we trained our own models, and we’ll work with you to customize those datasets for your vision.